Machine Learning as a Service (MLaaS): An introduction to Cloud-Native AI
MemoryMatters #40


Cloud computing and AI are coming together faster than ever, but machine learning accelerators see less than 15% utilization. This low usage reminds us of servers before virtualization that ran at just 4% efficiency. The Machine Learning as a Service (MLaaS) world now has a chance to optimize these resources.
AI workload deployment and management practices are changing fundamentally. Machine learning, particularly deep learning, needs significant GPU resources to train models. Datasets reaching 100 gigabytes move constantly through these systems. The supporting infrastructure requires massive power - a mid-sized data center uses as much electricity as thousands of homes. Some local governments have stopped approving new developments to protect their power grids.
Moving forward, MLaaS as cloud computing's next step forward must tackle efficiency problems and make AI more accessible. We'll get into the specific infrastructure that cloud-native AI needs, how centralizing ML workloads can boost resource usage, and show how MLaaS helps organizations of all sizes adopt AI more effectively.
Understanding Machine Learning as a Service (MLaaS)
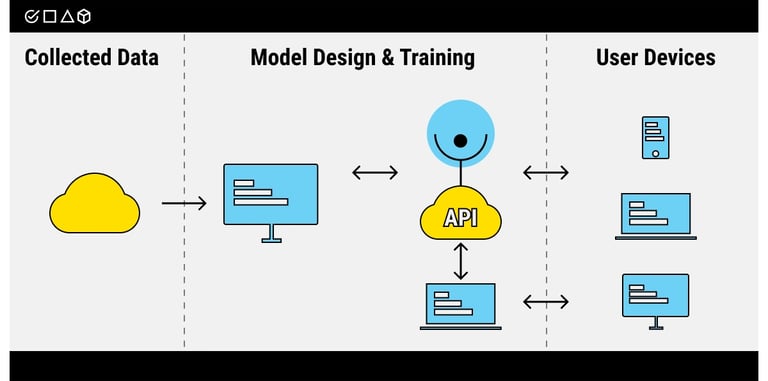
Image Source: Label Your Data
"MLaaS is a way to enjoy the benefits of machine learning without bearing the risks of designing your own models and avoiding the costs of collecting an expensive in-house crew of developers and data scientists to build your own ML platform from scratch." — Label Your Data Team, Data annotation and AI development platform experts
Machine Learning as a Service (MLaaS) represents the natural progress of cloud computing and artificial intelligence integration. Organizations now recognize the value of evidence-based insights, and MLaaS has become a vital technology that enables digital transformation in every industry.
What is MLaaS and how it works
MLaaS provides a detailed suite of cloud-based platforms that manage complex infrastructure requirements for machine learning workflows. These platforms cover everything in data pre-processing, model training, model evaluation, and prediction generation [1]. MLaaS builds on cloud architecture with containers and kubernetes, which creates a foundation like Software as a Service (SaaS) solutions [2].
This approach shines through its simplicity. Organizations can upload their data to cloud platforms and utilize pre-built machine learning algorithms to extract valuable insights. The prediction results become available through REST APIs that naturally connect with existing IT infrastructure [1]. These platforms use a pay-as-you-go model, so companies only pay for their actual computing resource usage [3].
Amazon (SageMaker), Microsoft (Azure Machine Learning), Google (AI Platform), and IBM (Watson Machine Learning) offer sophisticated MLaaS environments with different levels of automation and customization options [1]. Each platform offers unique tools from fully automated solutions to highly customizable frameworks that suit different technical expertise levels.
Benefits of MLaaS for businesses
MLaaS adoption brings substantial advantages to businesses of all sizes:
Democratized access: MLaaS makes advanced machine learning capabilities available to businesses of all sizes, not just those with deep pockets and specialized teams [4]
Cost efficiency: Companies can avoid large upfront expenditure by eliminating expensive hardware investments and maintenance costs [5]
Scalability: Businesses can adjust their machine learning operations to handle growing datasets and pay only for used resources [4]
Accelerated deployment: Pre-built models and simplified workflows help businesses implement ML solutions quickly - in hours or days instead of weeks or months [4]
Reduced complexity: Accessible interfaces and automated processes remove technical barriers so non-experts can develop and deploy machine learning solutions [6]
The MLaaS market shows remarkable growth. Valued at approximately $1 billion in 2020, experts project it to reach $8.5 billion in the coming years [4]. Some estimates suggest even more impressive growth, potentially hitting $304.82 billion by 2032 [7]. These numbers highlight the growing dependence on cloud-native AI solutions across industries.
MLaaS vs traditional ML deployment
Traditional machine learning deployment requires substantial investment in infrastructure, powerful hardware, specialized software, and a core team of data scientists [4]. The process needs complex setup procedures to configure servers, install libraries, and establish proper environments [5].
MLaaS substantially simplifies this process. Organizations can deploy models in minutes through web interfaces or APIs instead of spending weeks building infrastructure [5]. The service provider handles all backend complexities, which allows businesses to focus on their core competencies rather than managing technical infrastructure.
Resource utilization marks another vital difference. Traditional approaches often waste computing resources, especially with expensive GPU hardware. A single Nvidia GPU costs about $699, while cloud-based options like Google Cloud TPU v2 cost just $4.50 per hour [8]. This price gap means companies could run over 155 hours of cloud experiments before matching the original cost of one GPU [8].
MLaaS leads the charge in wider AI adoption as cloud services continue to evolve. It supports both enterprise-scale operations and small team innovations with equal efficiency.
The ML Lifecycle in the Cloud: Concept to Deployment
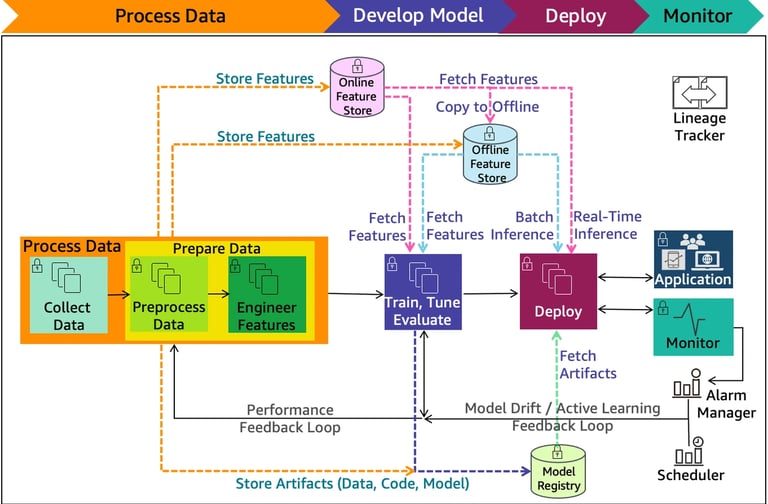
Image Source: AWS Documentation
Machine learning lifecycle in cloud environments follows a well-laid-out yet iterative path from concept through training to deployment. Each phase brings unique requirements and challenges that MLaaS platforms can address. This experience lights up why cloud-native AI implementation is becoming the preferred approach faster for organizations that embrace artificial intelligence.
Concept phase: learning data and models
Successful ML projects start with exploratory data analysis (EDA). Data scientists interact with datasets to understand their characteristics before building model prototypes [9]. This original phase needs high interaction and forms the foundations for future development.
Cloud platforms shine here. They offer specialized environments like Vertex AI Workbench or SageMaker Canvas that enable quick data exploration and visualization [10]. These tools help identify missing values, assess data quality, and assess the predictive power of features against target variables [11].
Resource consumption stays moderate during this conceptual stage as experimentation happens on smaller scales [12]. In spite of that, cloud-based notebook environments give even these preliminary explorations flexible computing resources that would get pricey to maintain on-premises.
Training phase: resource-intensive workloads
Model training begins when a concept shows promise—maybe the most compute-intensive stage in the ML lifecycle. This phase needs substantial resources to process big datasets and train complex models [13]. These resource needs include:
Training deep learning models often needs specialized processors like GPUs and TPUs to speed up operations through parallel computations [13]
Large models may need distributed computing across multiple nodes [14]
Training can involve hundreds of experiments to find optimal hyperparameters and model architectures [15]
Google's AI Platform or Amazon's SageMaker address these challenges. They automatically scale infrastructure from one to thousands of GPUs as needed [14]. Organizations can avoid costly infrastructure investments while still accessing cutting-edge hardware accelerators.
Deployment phase: inference and real-time use
Models must serve predictions in production environments after successful training. The deployment phase focuses on efficiency and responsiveness. Models need to deliver predictions with minimal latency [12].
Cloud-based MLaaS platforms make this transition easier through containerization and automated deployment pipelines [16]. They provide specialized environments for model serving, complete with monitoring tools that track performance metrics like prediction accuracy and latency [16].
Cloud providers offer low-latency inference endpoints with auto-scaling capabilities for real-time applications to handle varying traffic loads [17]. Applications can reliably access ML capabilities without managing complex infrastructure.
In fact, the end-to-end machine learning lifecycle in cloud environments represents a fundamental change in how organizations develop and implement AI. MLaaS platforms facilitate broader AI adoption across industries while streamlining processes by providing purpose-built tools for each phase—truly marking the next progress in cloud computing.
Infrastructure Needs for Cloud-Native AI
Cloud-Native AI needs reliable foundations to work well, especially since AI model data doubles every 18 months. This growth rate surpasses Moore's Law [18]. MLaaS represents cloud computing's next frontier, and traditional systems don't deal very well with its specialized architecture requirements.
Data storage and movement challenges
Cloud-native AI implementations face a basic challenge with adaptable data storage. ML workloads need elastic infrastructure that handles data of all types - structured, unstructured, and semi-structured information [19]. Different data formats make organization and access more complex.
Moving data creates additional hurdles. Large-scale models often use datasets bigger than 100 gigabytes. Moving this much data between storage and compute layers creates major bottlenecks. Cloud providers offer specialized answers like Dataflow for streaming ingestion and Datastream for change data capture [20]. Organizations should carefully plan their data movement patterns to maintain performance.
Compute resources: CPUs, GPUs, and DPUs
Cloud-Native AI's processing requirements call for a three-part approach to computing resources:
CPUs work best at sequential processing with fewer cores at high speeds, making them ideal for general computing tasks and orchestration [8]
GPUs use thousands of cores optimized for parallel processing and speed up AI workloads through massive parallelization [8]
DPUs (Data Processing Units) are newer processors built specifically for data-centric workloads that combine CPU cores with hardware accelerators and high-performance network interfaces [21]
Companies first used only CPUs for computing tasks. Later, GPUs became crucial for AI training and inference. The cost difference is remarkable - a single Nvidia GPU costs about $699, while Google Cloud TPU v2 costs only $4.50 per hour [22].
Networking and latency considerations
Latency plays a crucial role in AI's cloud performance. Network delays happen because of distance, congestion, or poor routing [23]. Data processing by AI models creates compute latency [24]. Poor code or complex operations lead to application latency [25].
Today's high-speed networks (400GbE and InfiniBand) work faster than internal server busses and deliver 50GB/s of bandwidth [26]. Well-designed systems can use this speed for better distributed AI computing.
Security and compliance requirements
MLaaS security becomes crucial because it processes user data on cloud servers. This raises concerns with sensitive data like medical or financial records [27]. Solutions like homomorphic encryption and trusted execution environments (TEEs) help protect information [3].
Legal compliance adds more complexity. AWS supports 143 security standards and compliance certifications, including HIPAA, GDPR, and FedRAMP [2]. These certifications help companies meet legal requirements while using cloud-native AI.
Centralizing ML Workloads for Efficiency
Machine learning operations' centralization has become a crucial strategy to maximize efficiency in enterprises. Uncontrolled infrastructure growth can eat away the economic advantages that cloud computing and AI collaborations promise.
Avoiding resource sprawl among teams
Teams that independently deploy ML infrastructure create resource sprawl, which results in isolated pockets of underused computing power. Industry observations indicate ML computational costs can skyrocket without proper management [28]. Many organizations moved their ML workloads to cloud platforms to reduce costs and spun up thousands of machines temporarily instead of buying dedicated servers. These benefits came with new challenges in management complexity and multi-cloud compatibility [28].
Pooling GPU and accelerator resources
Creating shared pools of Graphics Processing Units (GPUs) marks a transformation in ML infrastructure strategy. Organizations that pool specialized hardware resources achieve remarkable advantages:
Increased resource utilization by up to 4.1× compared to traditional deployments [29]
Reduced inference latency by 72.3% to 90.3% in production environments [30]
Improved throughput by 1.92× to 4.98× through optimized resource allocation [30]
Recent benchmarking provides compelling evidence where virtualized environments performed 4% better than bare metal for language and image processing workloads [31].
Virtualization and containerization benefits
Virtualization revolutionizes ML workload deployment methods. Research demonstrates MLPerf Inference benchmarks needed only 32 logical CPU cores and 128GB of memory, which allowed remaining capacity to support other workloads on identical systems [31]. GPU virtualization combined with Kubernetes lets users define resource limits per container and ensures precise allocation without overcommitting hardware [4].
Role of MLOps in managing MLaaS platforms
MLOps practices bind centralized ML infrastructure together effectively. These platforms include automated pipelines that standardize model development, testing, and deployment [7]. Kubeflow acts as a core component in numerous MLaaS implementations and provides various ML frameworks like TensorFlow, Keras, and PyTorch alongside development tools such as Jupyter notebooks [5]. MLOps also tracks model lineage, detects data drift, and maintains governance—essential requirements as AI adoption grows in industries of all sizes [32].
How MLaaS Supports the Growth of AI Adoption
The MLaaS market shows explosive growth and experts project it to reach $84.1 billion by 2033 with a remarkable CAGR of 25.88% [33]. This surge shows how Machine Learning as a Service has become the foundation that drives AI adoption in various industries.
Lowering entry barriers for smaller teams
MLaaS makes cognitive computing available by offering cost-effective solutions to organizations of all sizes [1]. Small and medium enterprises (SMEs) find great value in the pay-as-you-go model. It turns machine learning from a complex project into a plug-and-play solution [6].
Jake Gardner, Enterprise Account Executive at Domo, explains: "When it's a service, you take the whole platform administration piece away from the enterprise. That cuts down a lot of the headache and cost that traditionally surround data science" [1]. This availability helps smaller organizations scale their AI capabilities as they need.
Supporting cloud services trends in AI
MLaaS continues to develop alongside emerging cloud services trends. Two key developments shape this progress:
Automated Machine Learning (AutoML) - Platforms select and tune models autonomously without manual setup [6]
Edge + Cloud AI - MLaaS expands to process data closer to its source, which improves speed and reduces latency [6]
Amit Marathe, Director of AI & ML at Inseego Corp, shares his vision: "In the future, all businesses will be able to use MLaaS and self-driving data science platforms to generate real-time visual insights to save lives, improve productivity, increase profitability and transform their business" [1].
MLaaS stands as the next frontier in cloud computing. It creates an available pathway for AI adoption that works for both enterprise implementations and small team breakthroughs.
Closure Report
Machine Learning as a Service (MLaaS) is transforming cloud computing and AI implementation. It addresses a key issue: machine learning accelerators are underutilized at under 15% capacity, similar to pre-virtualization efficiency problems. The MLaaS market is projected to reach $84.1 billion by 2033, growing at a CAGR of 25.88%. This growth demands significant infrastructure, particularly with specialized processors like GPUs and TPUs that enhance AI workloads through parallelization. Resilient data storage is also essential, as training data doubles every 18 months, outpacing Moore's Law. Centralizing ML workloads improves efficiency, with pooled GPU resources increasing utilization by up to 4.1 times. This strategy merges virtualization and containerization, maximizing hardware value while maintaining flexibility. MLaaS democratizes access to sophisticated AI, offering more economical cloud-based options than traditional models.
The future of MLaaS is bright, with advancements in AutoML and Edge+Cloud integration simplifying AI implementation across industries. While challenges like security, compliance, and data movement exist, MLaaS is fundamentally reshaping AI deployment at scale.
References
[1] - https://www.hp.com/us-en/workstations/learning-hub/ai-for-all.html
[2] - https://aws.amazon.com/compliance/
[3] - https://dl.acm.org/doi/fullHtml/10.1145/3627106.3627145
[4] - https://medium.com/@serverwalainfra/ai-workload-optimization-using-kubernetes-and-gpu-virtualization-8963d83c2f99
[5] - https://www.ncbi.nlm.nih.gov/books/NBK602368/
[6] - https://predikly.com/machine-learning-as-a-service-how-us-businesses-can-leverage-ai-for-growth/
[7] - https://aws.amazon.com/what-is/mlops/
[8] - https://www.ibm.com/think/topics/cpu-vs-gpu-machine-learning
[9] - https://learn.microsoft.com/en-us/azure/machine-learning/tutorial-explore-data?view=azureml-api-2
[10] - https://cloud.google.com/products/ai
[11] - https://cloud.google.com/blog/products/ai-machine-learning/building-ml-models-with-eda-feature-selection
[12] - https://docs.run.ai/v2.20/Researcher/workloads/overviews/workload-types/
[13] - https://www.ibm.com/think/topics/ai-workloads
[14] - https://aws.amazon.com/sagemaker-ai/train/
[15] - https://developers.google.com/machine-learning/managing-ml-projects/phases
[16] - https://min.io/learn/ai-ml/ml-workloads
[17] - https://learn.microsoft.com/en-us/azure/ai-foundry/how-to/deploy-models-managed
[18] - https://www.cncf.io/wp-content/uploads/2024/03/cloud_native_ai24_031424a-2.pdf
[19] - https://medium.com/@selhorma/building-a-scalable-machine-learning-as-a-service-infrastructure-with-iaas-f53ca2ba5796
[20] - https://cloud.google.com/data-movement
[21] - https://blogs.nvidia.com/blog/whats-a-dpu-data-processing-unit/
[22] - https://neptune.ai/blog/machine-learning-as-a-service-what-it-is-when-to-use-it-and-what-are-the-best-tools-out-there
[23] - https://medium.com/@RocketMeUpNetworking/understanding-the-implications-of-network-latency-on-cloud-services-ad441d22b17e
[24] - https://galileo.ai/blog/understanding-latency-in-ai-what-it-is-and-how-it-works
[25] - https://aws.plainenglish.io/17-sources-of-latency-in-the-cloud-and-how-to-fix-them-checklist-ccd8f3bf3950
[26] - https://www.weka.io/blog/ai-ml/solving-latency-challenges-in-ai-data-centers/
[27] - https://people.iiis.tsinghua.edu.cn/~gaomy/pubs/temper.acsac23.pdf
[28] - https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/solutions/vmw-vlss-machine-learning-white-paper.pdf
[29] - https://www.theriseunion.com/en/blog/GPU-Pooling-for-Accelerated-AI-Training-and-Cost-Optimization.html
[30] - https://arxiv.org/html/2409.14961v1
[31] - https://blogs.vmware.com/performance/2024/05/magic-of-virtualized-ml-ai.html
[32] - https://learn.microsoft.com/en-us/azure/machine-learning/concept-model-management-and-deployment?view=azureml-api-2
[33] - https://www.imarcgroup.com/machine-learning-as-a-service-market
[34] - https://www.fortunebusinessinsights.com/machine-learning-as-a-service-mlaas-market-111575
[35] - https://www.stxnext.com/blog/what-is-machine-learning-as-a-service
[36] - https://www.topbots.com/comprehensive-guide-to-mlaas/
Linked to ObjectiveMind.ai